L’arithmétique des entiers n’est pas sûre par défaut : le contrat de dépassement que vous n’avez pas défini
- 16 juin 2026
- 11 mins de lecture
- Concepts de programmation , Qualité logicielle
Table des matières
Le défaut non sécurisé que vous utilisez tous les jours
On a tendance à considérer l’arithmétique entière comme « sécurisée par défaut ». Ce n’est pas le cas.
Utiliser +, - ou * sur des entiers introduit une faiblesse cachée dans votre code.
Ce risque devient réel dès que les limites ne sont pas explicitement prises en compte.
Le problème est simple : ces opérations supposent que le résultat tient dans le type entier choisi, mais cette hypothèse n’est généralement pas vérifiée.
En pratique, cette hypothèse reste souvent implicite. Lorsqu’elle échoue, l’arithmétique devient une source silencieuse de bugs.
C’est le même type de problème décrit dans La limite du silicium : pourquoi les calculs en virgule flottante et entiers échouent, où des hypothèses numériques échouent sans avertissement. Ici, le problème n’est pas la précision — c’est la plage de valeurs.
Pourquoi la division attire l’attention (et pas le reste)
La division est généralement traitée différemment.
En mathématiques, la division par zéro est interdite, et en programmation, elle est largement reconnue comme une opération invalide. En plus de cela, la division entière perd en précision, ce qui rend les développeurs plus prudents.
Par conséquent, la division est souvent protégée par des vérifications.
Mais l’addition, la soustraction et la multiplication ne suscitent pas les mêmes inquiétudes. En mathématiques, elles sont toujours définies. Aucune contrainte ne vous force à réfléchir aux limites.
Cette intuition se transpose en programmation, et c’est là que l’erreur apparaît.
Sur un ordinateur, les entiers sont finis. Chaque opération est bornée par les limites de représentation. Lorsque ces limites sont dépassées, le comportement n’est plus purement mathématique.
Donc le sujet de cet article n’est pas la division.
Ce sont les opérateurs auxquels on fait le plus confiance : +, - et *.
La question manquante
À chaque opération arithmétique, il existe une hypothèse implicite.
Que doit-il se passer si le résultat ne peut pas être représenté ?
Cette question est souvent non explicitement posée dans le code ou dans la conception. À la place, le comportement est hérité du langage, du compilateur ou du matériel.
C’est là que se trouve la racine du problème.
La même opération, des résultats différents
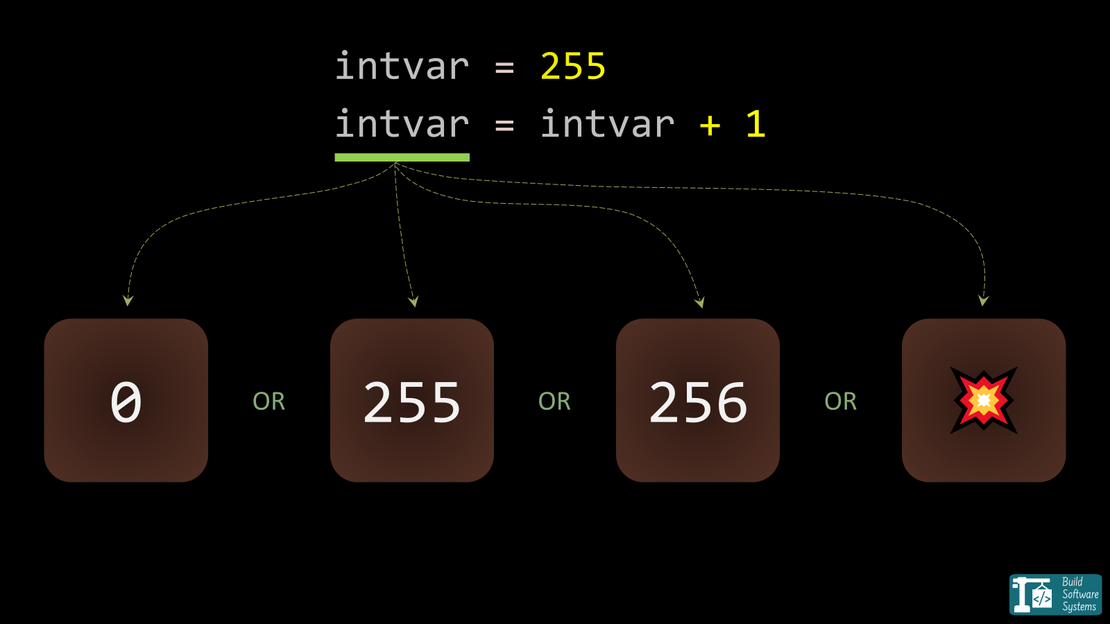
Considérons une simple addition qui dépasse la valeur maximale d’un entier.
Selon l’environnement, plusieurs choses peuvent se produire.
- La valeur peut boucler (wrap) et repartir depuis le minimum.
- Elle peut saturer et rester au maximum.
- Elle peut déclencher un panic ou une exception.
- Elle peut même être considérée comme impossible par le compilateur, conduisant à un comportement indéfini.
Tous ces comportements existent dans des systèmes réels. Le problème est que le comportement choisi est souvent implicite.
L’overflow est un choix de conception
Tout système qui effectue de l’arithmétique entière définit implicitement un modèle pour l’overflow et l’underflow. Il n’existe que quelques modèles pertinents, et chacun a des conséquences différentes.
1. Bouclage (arithmétique modulaire)
Un modèle courant est l’arithmétique modulaire, où les valeurs bouclent dans une plage fixe. Par exemple, ajouter un à la valeur maximale produit la valeur minimale.
1package main
2import "fmt"
3func main() {
4 // Créer un entier non signé sur 8 bits initialisé à 255
5 var number uint8 = 255
6 fmt.Println("Nombre initial :", number)
7 // Essayer d’ajouter 1
8 number = number + 1
9 fmt.Println("Après ajout de 1 :", number)
10}
Nombre initial : 255
Après ajout de 1 : 0
Ce comportement est naturel pour le matériel et utile dans des domaines comme le hachage, les buffers circulaires ou les numéros de séquence. Mais en dehors de ces cas, il introduit des bugs difficiles à détecter, car le résultat reste apparemment valide.
Tip
Pour des entiers non signés sur N bits, cela équivaut à effectuer l’opération modulo 2^N.
2. Saturation (Écrêtage)
Un autre modèle est la saturation. Dans ce cas, au lieu de boucler, les valeurs sont limitées à un minimum ou un maximum. Si une valeur dépasse la plage autorisée, elle reste à la borne.
1% Créer un uint8 initialisé à 255
2number = uint8(255);
3disp(['Nombre initial : ', num2str(number)])
4% Essayer d’ajouter 1
5number = number + 1;
6disp(['Après ajout de 1 : ', num2str(number)])
Nombre initial : 255
Après ajout de 1 : 255
Ce modèle est souvent utilisé en traitement d’image ou du signal, où dépasser une plage ne doit pas inverser ou corrompre le sens des données. L’inconvénient est que l’information est perdue silencieusement, même si c’est de manière contrôlée.
3. Panic / Exception
Un troisième modèle consiste à arrêter l’exécution. Dans ce cas, le programme panique, lance une exception ou plante lorsqu’un overflow se produit.
Cette approche est courante dans des environnements plus sûrs ou en mode debug. Elle transforme une corruption silencieuse en échec explicite, ce qui est souvent préférable dans des systèmes critiques comme la finance ou la sécurité.
4. Comportement indéfini
Un autre modèle consiste à supposer que l’overflow n’arrive jamais.
C’est l’un des modèles les plus dangereux (il a contribué à des défaillances comme les bugs logiciels de la fusée Ariane 5 et du Boeing 787).
Dans des langages comme C et C++, l’overflow d’entiers signés est un comportement indéfini. Le compilateur est autorisé à supposer qu’il n’arrive pas, ce qui signifie qu’il peut supprimer des vérifications ou optimiser du code d’une manière qui casse la logique si un overflow survient réellement.
Par exemple, si vous avez x + 1 > x, le compilateur peut optimiser cela en true car il suppose que x + 1 ne déborde jamais.
Si x vaut INT_MAX, x + 1 déborde, et la comparaison devient INT_MIN > INT_MAX, ce qui est false.
5. Précision arbitraire
Enfin, certains langages évitent totalement l’overflow en permettant aux entiers de grandir dynamiquement. Dans ce modèle, les valeurs s’étendent selon les besoins pour représenter exactement le résultat.
Cela élimine l’overflow comme mode d’échec, mais introduit des compromis en termes de performance et de mémoire.
Aucun de ces modèles n’est universellement correct. Chacun est adapté à certains contextes.
Le problème n’est pas de choisir le mauvais. Le problème est de ne pas choisir du tout.
Qu’en est-il de la soustraction et de la multiplication ?
Le même problème s’applique au-delà de l’addition. La soustraction peut produire un underflow.
Par exemple, soustraire une valeur plus grande d’une plus petite dans un type non signé produit une grande valeur positive au lieu d’un résultat négatif. C’est souvent contre-intuitif et conduit à une logique incorrecte lorsque l’on suppose que les valeurs restent dans des bornes attendues.
La multiplication est encore plus dangereuse, car elle fait croître les valeurs plus rapidement. Il est facile de dépasser les limites sans s’en rendre compte, en particulier lorsque l’on combine des entrées utilisateur, des facteurs d’échelle ou des valeurs accumulées. Contrairement à l’addition, où les limites peuvent être atteintes progressivement, la multiplication peut les franchir en une seule étape.
Le problème de fond reste le même. L’opération est valide en mathématiques, mais la représentation ne garantit pas de pouvoir contenir le résultat.
Warning
Les opérateurs comme ++ et --, ainsi que les affectations composées comme +=, -=, *=, et /=, suivent exactement les mêmes règles.
Ce ne sont que des raccourcis pour des opérations arithmétiques.
Cela les rend faciles à négliger.
Un incrément (++) ou += peut provoquer un overflow, et un décrément (--) ou -= peut provoquer un underflow, comme n’importe quelle autre opération. La multiplication et la division via *= et /= présentent les mêmes risques.
Comme ils masquent l’opération derrière une syntaxe, ils peuvent introduire des bugs de limites dans des endroits qui semblent inoffensifs (comme des compteurs de boucle ou des mises à jour d’index).
À propos de la négation
La négation (-x) est souvent considérée comme sûre car elle est simple et unaire, mais elle est en réalité équivalente à 0 - x et suit les mêmes règles que la soustraction.
Pour les entiers signés, il existe un cas limite critique.
La valeur minimale représentable n’a pas de contrepartie positive en représentation en complément à deux.
Changer son signe produit une valeur qui ne peut pas être représentée (overflow).
Sur un entier signé sur 8 bits, la plage est [-128, 127].
Changer le signe de -128 nécessiterait +128, qui n’existe pas dans cette plage.
Si le système utilise une arithmétique modulaire, l’opération se comporte comme 0 - (-128) = 0 + 128 = 128, ce qui déborde et boucle vers -128, produisant la même valeur.
Dans un modèle saturant, le résultat serait limité à 127, la valeur maximale représentable.
Ces deux comportements découlent directement de la définition de la soustraction sous des limites finies.
Pour les entiers non signés, il n’existe pas de cas limite particulier comme pour les minimums signés.
Cela signifie que la négation n’est pas une opération spéciale. C’est un autre point où les limites de représentation et le modèle arithmétique choisi déterminent le résultat.
À propos de la division
La division est généralement traitée avec plus de précautions, mais elle n’est pas totalement sûre non plus.
La division par zéro est explicitement invalide et est généralement gérée par le langage ou l’environnement d’exécution. Cependant, il existe encore des cas limites souvent ignorés.
La division entière tronque les résultats, ce qui peut ne pas correspondre aux attentes.
Il existe aussi des cas d’overflow, comme la division de l’entier signé minimal par -1 dans certains langages, qui ne peut pas être représentée et mène à un comportement indéfini ou dépendant de l’implémentation.
Ainsi, même si la division reçoit plus d’attention, elle n’échappe pas à cette classe de problèmes.
Les comportements par défaut ne sont pas uniformes
À ce stade, il doit être clair que le comportement dépend fortement du langage.
Certains langages définissent un comportement de bouclage pour les entiers signés et non signés (ex. : Go, Java, C#).
D’autres font la distinction, autorisant le bouclage pour les valeurs non signées tout en traitant l’overflow signé comme indéfini (ex. : C, C++, Objective-C, Fortran).
Certains langages saturent les valeurs au lieu de boucler (ex. : MATLAB/Octave).
D’autres évitent totalement l’overflow en utilisant des entiers à précision arbitraire (ex. : Python).
Certains langages détectent l’overflow et arrêtent l’exécution dans certains modes (ex. : Rust, Zig, Swift).
Certains convertissent même les entiers en nombres à virgule flottante en cas d’overflow (ex. : PHP).
D’autres utilisent des nombres à virgule flottante pour toutes les opérations numériques (ex. : JavaScript, Lua < 5.3).
Il n’existe aucune règle universelle.
Cela signifie que déplacer du code entre langages, ou même entre configurations de compilation d’un même langage, peut modifier le comportement arithmétique sans modifier le code lui-même.
C’est un risque que beaucoup de systèmes ne prennent pas en compte.
Voici un résumé pratique des comportements par défaut (pour +, - et *).
| Language | Entier signé | Entier non signé |
|---|---|---|
| MATLAB / Octave | Saturation | idem |
| C | Comportement indéfini | Bouclage |
| C++ | Comportement indéfini | Bouclage |
| Objective-C | Comportement indéfini | Bouclage |
| Fortran | Comportement indéfini | Bouclage (récent) |
| Go | Bouclage | idem |
| Java | Bouclage | idem |
| Kotlin | Bouclage | idem |
| Lua >= 5.3 | Bouclage | idem |
| C# | Bouclage (unchecked), Exception (checked) | idem |
| Rust | Panic (debug), Bouclage (release) | idem |
| Swift | Panic/Trap | idem |
| Zig | Panic/Trap | idem |
| Python | Précision arbitraire | idem |
| JavaScript | Float (IEEE 754) ou Bigint (précision arbitraire) | N/A ou Bigint (précision arbitraire) |
| Lua < 5.3 | Float (IEEE 754) en interne | N/A |
| PHP | Conversion en float (IEEE 754) en cas d’overflow | N/A |
Concevoir avec un modèle explicite
La seule manière fiable de gérer cela est de rendre explicite le comportement en cas d’overflow.
Commencez par définir la plage de valeurs valides dans votre système. Cela inclut non seulement les valeurs actuelles mais aussi les résultats de toutes les opérations pouvant être effectuées sur celles-ci.
Ensuite, définissez ce qui doit se produire lorsque cette plage est dépassée. La valeur doit-elle boucler ? Être limitée ? Le programme doit-il s’arrêter ? Ou l’opération doit-elle être empêchée ?
Une fois cette décision prise, appliquez-la de manière cohérente.
Cela peut être fait via des fonctionnalités du langage comme les opérations arithmétiques vérifiées, via des validations explicites avant d’effectuer les opérations, ou en utilisant des types et des abstractions qui encodent directement les contraintes dans le système.
Ce qui compte, c’est que le comportement soit défini et appliqué de manière cohérente.
Bulletin d'information
Abonnez-vous à notre bulletin d'information et restez informé(e).
Points clés
L’arithmétique entière n’est pas intrinsèquement sûre. Elle semble sûre uniquement parce que les échecs sont souvent silencieux.
L’overflow et l’underflow ne sont pas des cas limites. Ce sont des résultats normaux d’opérations sur des représentations finies.
Le vrai problème n’est pas que ces comportements existent, mais qu’ils sont souvent implicites et incohérents dans un système.
Si vous utilisez l’arithmétique entière, vous devez décider comment votre système gère ces cas. Sinon, cette décision sera prise pour vous — par le langage, le compilateur et le matériel — et elle pourrait ne pas correspondre à vos attentes.